
html für Linguist/inn/en
Ralf Vollmann
Grundkenntnisse in HTML werden in dieser Besprechung vorausgesetzt. Dieser Text überlegt, wie man HTML+CSS dafür verwenden kann, professionell strukturierte Texte zu verfassen.
Die meisten Menschen gestalten ihre Texte, während sie schreiben. Sie rücken ein, stellen kursiv, vergrößern Überschriften, etc.. Das ist im Grunde eine altmodische Art, mit Texten umzugehen. Wenn man mit der Hand schreibt oder auf einer Schreibmaschine tippt, ist diese Vorgehensweise angebracht. Am Computer hingegen kann man die Struktur von Texten systematischer behandeln: Mann kann festlege, das hier ist eine "Überschrift" – nicht bloß ein "großer Text". Der Vorteil davon ist, daß man anhand dieser Struktur das Aussehen beliebig verändern könnte: "Alle Überschriften sollen größer/kleiner sein, oder blau statt rot." Wie zu zeigen sein wird, besteht ein Text aus nur sehr wenigen verschiedenen Subtexttypen. Es genügt, eine Handvoll dieser Typen festzulegen und kann für immer auf das "Formatieren von Text" ganz verzichten. Man schafft nur eine Struktur.
ÜBERSCHRIFT 1: 01. Einleitung
ÜBERSCHRIFT 2: 01.01. Grundlagen
BODYTEXT: Die Kindersprachentwicklung wird seit dem 19. Jh. im Rahmen der ...
ZITAT: ...
BODYTEXT: ...
ÜBERSCHRIFT 2: 01.02. ...
Es gibt einen grundlegenden Unterschied zwischen dem Schreiben von Texten einerseits und deren Formatierung andererseits. Es ist auch ein Unterschied zwischen dem konkreten Aussehen von Textteilen und deren Funktion als Teil des Texts. Beispielsweise zitiert man etwas, und im Aussehen des Textes bedeutet das, daß der Text ein eigener Absatz, eingerückt und eventuell mit einem kleineren Schriftgrad dargestellt wird. Professionelle Systeme wie LATEX oder frühere Desktop-Publishing-Software haben diese beiden Bereiche (naja, teilweise) getrennt. In solchen Systemen definiert man (idealerweise) nicht, daß ein Textstück mit großer Schrift und zentriert und rot dargestellt werden soll, sondern es wird nur angegeben, daß dieses Textstück eine Überschrift der zweiten Ebene ist, oder ein normaler Text, oder ein Zitat, oder ein Sprachbeispiel, usw.. Die Formatierung für solche Textteile war grundlegend an anderer Stelle definiert. HTML für sich folgt diesem Prinzip grundsätzlich auch:
<h1>01. Einleitung</h1>
<p>Die ist ein normaler Absatz.</p>
<blockquote>Dies ist ein Zitat</blockquote>
Textverarbeitungssoftware, in heutiger Zeit in erster Linie MS-Word und LibreOffice.Write, können das zwar traditionell ("Formatvorlagen"), gehen aber mit jeder neuen Version in die entgegengesetzte Richtung, wobei sie sich selbst gewissermaßen entprofessionalisieren zugunsten einer Mehrheit von Benutzerinnen und Benutzern, die nicht systematisch arbeiten wollen oder können – sondern so, wie man es immer schon gemacht hat: mit vielen Formatieranweisungen. Es gibt also die Formatvorlagen, es gibt aber gleichzeitig, viel prominenter, das “wilde” Formatieren mit Hilfe direkter Formatbefehle. Es ist ein großer Schaden für die Automatisierung des Umgangs mit Texten, daß es keine verbindliche Formatvorlagenkonvention gibt wie beispielsweise in LATEX, an die man sich “zwangsweise” halten muß (Standardisierung). Vielmehr sind die meisten Texte aus einer Textverarbeitung schon instabil vor lauter Fehlern im Code, von dem sie reichlich haben. Die Benutzerinnen und Benutzer merken das nicht, weil sie WYSIWYG arbeiten ("What you see is what you get"), d.h., am Bildschirm schaut der Text schon aus wie gedruckt. Wenn man LATEX ode HTML schreibt, arbeitet man meistens WYSIWIM ("What you see is what you mean"), d.h., man definiert, welche Art von Text man gerade schreibt, nicht, wie er aussieht. Er sieht immer gleich aus im Editor, plus Annotierungen:
&l;th1>01. Einleitung</h1>
<p>Die ist ein normaler Absatz.</p>
<blockquote>Dies ist ein Zitat</blockquote>
Viele Menschen "bevorzugen" WYSIWYG, aber vielleicht haben sie nur die Vorzüge von WYSIWYM noch nicht ausreichend verstanden. Viele Editoren erleichtern WYSIWYM durch farbige Markierungen der Annotierungen. Der Vorteil von WYSIWYM ist, daß man hinschreiben kann, was man "will"; man muß nicht dem System indirekt mitteilen, was man möchte.

Abb.: "syntax highlighting" ("Hervorhebungsmodus") erleichtert WYSIWYM.
Die Ausrichtung der Textverarbeitungssysteme auf nichtprofessionelle ungelernte Benutzer, die nicht lernen wollen, was sie bereits zu wissen glauben, ist fatal für die Funktionalität dieser Programme. Man kann darüber nachdenken, wieviel Produktivität zerstört wird, wenn Leute ohne Plan Formulare entwerfen und Texte immer wieder neu "irgendwie" formatieren und reparieren; wieviel Überarbeitungszeit notwendig ist, wenn ein Text nicht systematisch formatiert ist. WENN ein Text systematisch mit definierten Formatvorlagen vorliegt, ist eine Änderung immer nur eine Frage von wenigen Minuten; man ändert die Formatvorlage, fertig. Amn schlimmsten, man wird von dieser Software gezwungen, sich dieser Vorgangsweise teilweise anzupassen.
Es ist eigentlich erstaunlich, aber eine Tatsache, daß der Drucksatz, das Ergebnis, von MS-WORD seit vielen Jahren nicht verbessert wird (Flatterrand unten oder unrealistisch große Absatzabstände auf der letzten Seite, keine Kontrolle unschöner Abteilungsergebnisse, obligatorische, teilweise falsche Spracherkennung und daraus folgend falsches Abteilen, usw. – Fehler durch “automatische Korrektur”), obwohl das Programm ständig in neuen Varianten auf den Markt kommt – deren “Innovationen” jedenfalls nicht professionellen Konsument/inn/en nützen. Seit auch noch die Bedienoberfläche "intuitiv" ist, kann man überhaupt nicht mehr effizient arbeiten.
Diese Programme konzentrieren sich auf quick&dirty-Formatierung, auf Rechtschreibprüfung und ähnlich unnützes Zeug. Der Export von und nach HTML ist gleichzeitig seit vielen Jahren gleich schlecht – gerade der Bereich Formatvorlagen rutscht immer weiter in den Hintergrund, obwohl er theoretisch vorllentwickelt vorläge.
LATEX ist praktisch gesehen durchaus auch problematisch, weil es am Monitor schwer zu lesen, technologisch veraltet (UNICODE wurde erst hinzugefügt, es gibt immer noch Probleme), durch sehr zahlreiche Zusatzpakete ziemlich unübersichtlich und eben ganz auf den Ausdruck ausgerichtet ist. Genaugenommen verwendet es Formatvorlagen nur implizit; man kann selbst keine Formatvorlagen angeben, sondern nur Direktformatierungen einfügen; naja, man kann selbst Makros schreiben, das entspricht einer Formatvorlage. Auch ist LATEX als Code (am Bildschirm) unangenehm zu lesen (z.B. wegen der merkwürdigen Codes für phonologische Zeichen und die allgemeinen Schwierigkeiten mit fremden Schriften – kein Unicode). Weiters ist LATEX nicht fehlertolerant; d.h., wenn im Code Fehler sind, wird der Text oft gar nicht dargestellt.
Es gibt also eigentlich keine zufriedenstellende Software, die so professionell und einfach zu bedienen ist wie beispielsweise die MS-Word-Version von 1999, als professionelle Merkmale noch im Vordergrund standen. LibreOffice.Write zeigt ein merkwürdiges Verhalten mit Absatzmarken, und LATEX ist im Vergleich zu heute verbreiteter Software generell exotisch. Es gibt einige “authoring systems” wie DOCBOOK, die Formatvorlagen anwenden, aber für mich nicht zufriedenstellend (zu stark spezialisiert für bestimmte Zwecke). An diesem Punkt kommt der Hinweis auf HTML; HTML ist sehr weit verbreitet, wird ständig entwickelt, ist sehr einfach, und kann sehr viel (wenngleich nicht alles).
HTML diente von Anfang an nur der Darstellung am Monitor, aber es ist immer innovativ und wird ständig mit großer Energie verbessert, es ist inzwischen vollständig UNICODE-fähig (Jeder Text ist "WYSIWYG" im Editor lesbar, was die Zeichen selbst betrifft), es kann einerseits wie LATEX behandelt werden, ist vollkommen plattformunabhängig (reiner Text), daher überall lesbar (GNU/LINUX und MS), und in Verbindung mit CSS auch in bezug auf Formatvorlagen mächtig. Es ist für den Ausdruck nur schlecht vorbereitet und hat keine Fußnotenverwaltung; auch der Seitenumbruch wird nur marginal kontrolliert. Da aber moderne Textverarbeitungssysteme HTML mit CSS korrekt importieren, steht dem Ausdruck mit Hilfe von MS-Word oder LibreOffice.Write wenig im Weg. “Wenig”, weil die genannten Programme einzelne kleinere Probleme machen. Übrigens, wenn HTML-Code nicht stimmt, wird er einfach ignoriert (Fehlertoleranz), das ist viel angenehmer als die gefürchtete LATEX-Fehlersuche.
Mit HTML bekommt man daher teilweise das Beste aus der WYSIWYM- und WYSISWG-Philosophie: Man schreibt WYSIWYM in irgendeinem Texteditor, und man kann den Ausdruck mittels z.B. MS-Word oder LibreOffice.Write vorher noch kontrollieren: WYSIWYG. Beim Umformen von HTML direkt in PDF mittels eines Druckertreibers hat man nur wenig direkte Kontrolle, es geht aber auch.
Schließlich sollte man auch berücksichtigen, daß die meisten Texte nicht jenes Ausmaß an Formatierung und Umgebung brauchen, wie Textverarbeitungssoftware unausweichlich mit sich bringt. Was mich betrifft, bringt ein schneller Texteditor mit sehr praktischen TextBEarbeitungsfunktionen sehr viel mehr Arbeitszufriedenheit mit sich als ein schwerfälliges eigenwilliges System, das ununterbrochen irgendetwas formattechnisch anders darstellt, als man es selbst vielleicht wollen würde.
Es ist viel schwieriger, einen Text aus MS-Word oder LibreOffice.Write in HTML weiterzuverarbeiten, weil diese Systeme einen unnötigen unsauberen Code schreiben, der sowohl Formatvorlagen als auch überbordend viele Direktanweisungen hinterlassen.

Abb.: Code, der von MS-Word erzeugt wurde. Die css-Angaben nehmen das halbe File ein, zusätzlich wird individuelle Formatierung hinzugefügt.
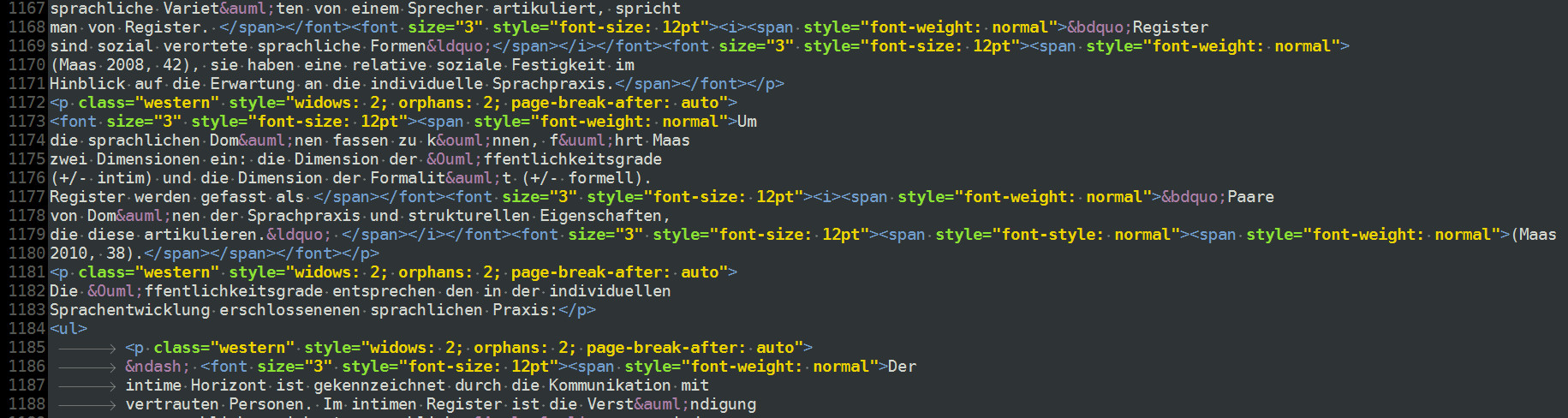
Abb.: Code, der von LibreOffice.Write erzeugt wurde. Noch schlimmer.
Man sieht an diesen Beispielen, was diese Software tut: Sie verwendet einerseits Formatvorlagen (class=), andererseits individuelle Formatierungen. Letzteres ist absolut unnötig, weil Textteile nicht anders aussehen sollten, als sie per Formatvorlage definiert wurden.
Ein anderer wichtiger Aspekt hierbei ist die Trennung verschiedener Informationseinheiten, z.B. Text vs. Bild. In Textverarbeitungssystemen werden Bilder “eingebettet” und sind solcherart meist verantwortlich für den größten Teil der Dateigröße, und in der Folge für Abstürze oder Verlangsamung. In WYSIWYM (LATEX, HTML) bleiben Bilder immer eigene Dateien und werden nur bei der Darstellung eingebunden. Die Textdatei bleibt klein, stabil und übersichtlich.
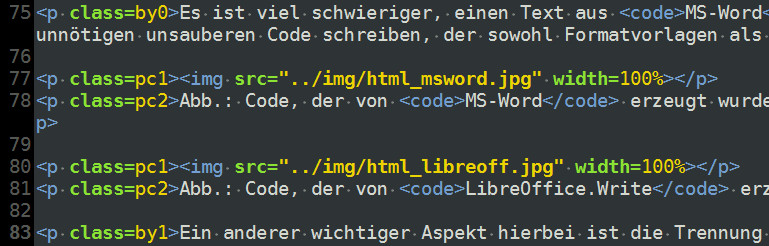
Abb.: Zwei Bilder in HTML: Pfad und Dateiname.
MS-WINDOWS/APPLE und MS-OFFICE als Hauptumgebung können sich nur auf Basis von Unwissenheit als fast ausschließliche Arbeitsumgebung halten. GNU/LINUX-Systeme sind wesentlich leichter zu bedienen, sie funktionieren meist besser und schneller. GNU/LINUX ist dominierend im Internet, vollständig auf UNICODE eingestellt, und wird ständig offen weiterentwickelt und adaptiert. Im Gegensatz zu einer MS-WINDOWS-Installation und den unvermeidlichen Problemen mit Viren, etc. ist GNU/LINUX gewöhnlich in 20min installiert, in 1h perfekt, und anschließend wartungs- und virenfrei. GNU/LINUX-Systeme laufen in der Regel sogar ohne Installation (Live-CD), sodaß man vorher alles testen kann. "Probleme" tauchen meist dann auf, wenn die Industrie bewußt Probleme macht – es liegt nicht an GNU/LINUX. Am wichtigsten ist: Sie respektieren die Freiheit der Benützer, mit ihrem Computer das zu tun, was SIE tun wollen. Im Gegensatz zu einer Software, die nicht verkauft, sondern "lizenziert" wird, die man weder ansehen noch verändern darf, und von der man nicht genau weiß, was sie eigentlich tut (z.B. ununterbrochen "nach Hause telephonieren").
Text hat zwei Instanzen: Die erste Zeile nach der Überschrift hat ein wenig Abstand nach oben und die erste Zeile ist NICHT eingerückt. Dies gilt auch nach Tabellen oder Abbildungen.
Jede folgende Zeile hat keinen Abstand zur vorherigen Zeile und die erste Zeile ist eingerückt. So wie hier gerade. Dieser Absatz wird gleich nochmal wiederholt, um einen Folgeabsatz darzustellen.
Jede folgende Zeile hat keinen Abstand zur vorherigen Zeile und die erste Zeile ist eingerückt. So wie hier gerade. Dieser Absatz wird gleich nochmal wiederholt, um einen Folgeabsatz darzustellen.
— Aufzählungen werden viel zu viel verwendet.
— In Textverarbeitungssystemen sind Aufzählungen schlecht integriert; man kann sie kaum global löschen oder verarbeiten.
— Auch in html würde ich das li-Element vermeiden; v.a. weil es als LIST in Textverarbeitung importiert wird.
— Diese Liste ist mit css definiert und somit im Grunde eine Serie normaler Absätze mit einem Bindestrich am Anfang.
Die Tabellenfunktion wird sehr oft völlig falsch verwendet. Zunächst einmal möge man selbstgebastelte Tabellen mittels zahlreicher Tabulatoren gar nicht verwenden. Weiters sollten Zeilenumbrüche in einem Tabellenfeld vermieden werden – das ist doch eine neue Tabellenzeile! Eine Tabelle kann man sehr leicht so gestalten (1. Schritt):
Tabelle vorbereiten (1. Schritt)
Spalte1$Spalte2$Spalte3$Spalte4$
12$14$20$15
12$14$20$15
12$14$20$15
Oder schöner:
Tabelle vorbereiten (1. Schritt)
Spalte1 $Spalte2 $Spalte3 $Spalte4
12 $14 $20 $15
12 $14 $20 $15
12 $14 $20 $15
Hier wurde einfach ein Zeichen verwendet, das ansonsten nicht verwendet wird; dies ist nun die Spaltentrennung. Mittels dieser Trennung kann mit verschiedener Software eine Tabelle erstellt werden.
| (01) | Umgewandelt in eine Tabelle (2. Schritt) | |||
| Spalte | Spalte | Spalte | Spalte | |
| Spalte | Spalte | Spalte | Spalte | |
| Spalte | Spalte | Spalte | Spalte | |
Es ist sinnvoll, links immer eine Numerierung, also eine eigene Spalte, einzufügen.
Die folgende Tabelle ist unnötig kompliziert und sollte meistens vermieden werden:
| (02) | Derlei sollte man möglichst vermeiden: | |||
| Spalte 1 | Spalte 2 | Spalte 3 | Spalte 4 | |
| Spalte 1 | Spalte 2+3 | rowspan | ||
| Spalte | Spalte | |||
Die linguistische Anwendung von Tabellen ist das glossierte Sprachbeispiel; dazu weiter unten.
Im folgenden wird erklärt, wie man Text und Darstellung getrennt behandelt. Dazu ist html mit css eine gute (= einfache) Lösung, die durch den unabhängigen Standard von HTML und CSS voll kompatibel und plattformunabhängig und damit nicht einschränkend ist.
— Geschrieben wird nur Text.
— Getaggt wird mit reinen html-Tags mit Verweisen auf Formatvorlagen.
— Formatvorlagen befinden sich in einem eigenen File "style.css", weshalb sie bei der Arbeit nicht weiter wichtig sind.
— Darstellung mit jedem Browser und manchen Editoren möglich.
— für schöneren Ausdruck kann kann das File in ein Textverarbeitungssystem importieren und mit höchstens sehr geringfügigen Änderungen ausdrucken.
Warum “html für Linguist/inn/en”? – wir benötigen die Darstellung von glossierten Sprachbeispielen, eine selten unterstützte Funktion. Dazu muß man auch in html ein bißchen basteln, aber nicht schlimmer als überall sonst.
Problem 1: Glossierte Sprachbeispiele werden von Software gewöhnlich nicht vorgesehen.
Problem 2: Fehlgebrauch von Textverarbeitungsfunktionen (ein Beispiel: wahlloser Einsatz von Tabulatoren und Spaces) macht Texte sehr unangenehm, inkompatibel und letztlich nicht mehr (ohne Riesenaufwand) strukturierbar.
Problem 3: Die Arbeitsweise mit Textverarbeitung (WYSIWYG) scheint die meisten User zur Unstrukturiertheit zu verleiten (Einrücken und Herumformatieren statt Strukturieren); Daher WYSIWYM ("what you see is what you mean"): nicht Formatierungen, sondern Textklassenbezeichnungen: Überschrift, Zitat, Text, Beispiel, …
Problem 4: Kompatibilität und dadurch Erhalt der Daten und Texte (HTML bleibt wohl immer kompatibel oder umschreibbar); kodierte Sonderzeichen können nicht verlorengehen und sind in jeder Software verwendbar.
HTML ist eine Seitenbeschreibungssprache; man kann diese online und rasch lernen (Suche: “HTML Tutorial”). Es funktioniert grundsätzlich so, daß Textteile mit Tags umschlossen werden, z.B. “<cite>‘Zitat Zitat Zitat Zitat’</cite>”. Dieser Code mit Text wird automatisch von einem HTML-Interpreter so dargestellt: ‘Zitat Zitat Zitat Zitat’. Ein neues, noch nicht von jedem Import unterstütztes Merkmal ist <q> (quotation): Zitat Zitat Zitat Zitat
(Die Apostrophe werden hierbei automatisch hinzugefügt).
| (01) | Möglichkeiten für ein Inline-Zitat | ||
| Einfach kursivsetzen | Befehl: <i> | Formatbefehl für kursiv | |
| Mit dem CITE-Element | Befehl: <cite> | alter Befehl, benötigt auch Apostrophe | |
Mit dem q-Element | Befehl: <q> | neuer Befehl, fügt Apostrophe selbst ein | |
HTML enthält rudimentär Formatvorlagen (p = paragraph; h1 = überschrift 1, blockquote = zitat, usw.) und direkte Formatierungen (i = italic/kursiv, b = bold/fett, u = underline/unterstrichen, usw.). Mann kann zu den rudimentären Formatvorlagen Direktformatierungen hinzufügen (z.B. <h1><font size="20"><font color=red>), doch wird dies NICHT empfohlen, sondern auf css verwiesen.
CSS kann man auch online und rasch lernen. Es handelt sich um Format-Definitionen, wie selbstdefinierte Elemente darzustellen sind. Dazu wird in einem eigenen File jedes Format definiert. Diese Funktionen können dann überlappen und kaskadieren dann, daher der Name. Das muß man nicht ganz verstehen :-) Es genügt zu wissen, daß "dort" die Formatierung festgelegt ist. Im STYLESHEET steht beispielsweise:
| (02) | style.css-Ausschnitt |
| .h1 { color: red ; font-size: 20 } |
... und das bewirkt, daß ALLE Überschriften der Ebene 1 (h1) rot und mit Schriftgröße 20 dargestellt werden. Würde man "color: green" hinschreiben, wären ab sofort alle Überschriften grün; usw.. Mit anderen Worten, wir müssen nur wissen, welche TAGs definiert sind, und schon können wir immer einheitlich formatieren, ohne uns selbst um die Formatierung zu kümmern.
Weiter unten wird vorgeschlagen, welche Formate man definieren soll, wie man sie nennen könnte, und wie man sie in HTML verwendet. Fertig – im übrigen denken wir nur noch über linguistische Fragen nach, nicht über Formatierungen.
Wir können auch die die css-Funktionen vor allem auf eine einzige Funktion reduzieren: class. Wir geben im css nur Absatzformatierungen an, und in der html-Datei schreibt man immer ca. folgendes: <p class=bodytext>, <p class=quotation>, usw.. Welche Kategorien notwendig sind, wird weiter unten besprochen.
UNICODE ist der modernste internationale Standard für Schriftzeichenkodierungen für alle Sprachen der Welt. Man sollte das ältere ASCII/ANSI aufgeben und sich dem UNICODE zuwenden. In Unicode kodierte Files haben kein Problem, jedes bekannte Schriftzeichen der Welt darzustellen (außer Schriftzeichen, die noch nicht implementiert sind): Ƥ ǝ Ẳ ẵ ể Ử ț ṭ ṛ ᶮ. Jedes dieser Zeichen kann entweder so in einer Unicode-Datei gespeichert sein, oder man schreibt den Code der Sonderzeichen. Kodiert sieht dieser "Text" so aus: ƤǝẲẵểỬ țṭṛᶮ. Das sind die Unicode-Nummern, unter denen das gewünschte Zeichen festgelegt ist. In einem UNICODE-File kann man diese Zeichen sehen, in einer ISO-8859-1- (oder ISO-8859-15-) Datei sieht man NUR diese Kodierungen, und in beiden Fällen sieht man die Zeichen im Browser. Ersteres ist also auch im Quelltext zu lesen, und das ist sehr bequem. Leider wird UNICODE unter MS-Windows nach wie vor nur "großteils" unterstützt. Ein guter kostenloser Unicode-Editor (extra für fremde Sprachen) für MS-Systeme (mit anderen Schwächen) ist BABELPAD. GNU/Linux-Systeme sind vollständig auf UNICODE umgestellt, jeder Editor ist geeignet; einfacherweise kann man GEDIT verwenden, einen einfachen Editor, der relativ bequem ist. Professionell, aber eigenwillig zu bedienen, ist EMACS (den es auch für MS-WINDOWS gibt), bzw., evtl. noch schlimmer VI bzw. VIM.
UNICODE-Fonts enthalten dennoch oft nur wenige Zeichen, nicht alle möglichen. Daher wird oft gemischt (Darstellung von Zeichen mit Hilfe anderer Fonts), wodurch nicht immer ein optimaler Output möglich ist. In MS-WINDOWS hat man immer wieder Ärger mit falschen Zeichen, wenn man IPA verwenden möchte und der gewählte Font diese Zeichen nicht enthält: Die Schriftzeichen sind dann nicht immer genau gleich groß oder haben verschiedenes Design. Ein anderes Beispiel für diese Problematik:
Hier passen die Pfeilspitzen manchmal nicht genau zur Linie: ←──── ────→
Der freie Font “Linux Libertine” ist sehr schön und enthält alle lateinischen Zeichen, also auch IPA (international phonetic alphabet). Für die Pfeile und Linien gibt es auch manchmal Darstellungsprobleme, aber das liegt nur an den verwendeten Fonts. Das folgende Diagramm enthält verschiedene Graphikelemente, die nicht immer richtig (ganz gleichmäßig) angezeigt werden; alles wurde richtig gemacht, aber die Fonts zur Darstellung sind gemischt:
CP ┌────────┴────────┐ XP C' ↑│ ┌────────┴────────┐ │ C IP │ │ ┌────────┴────────┐ │ │ NP I' │ │ ┌────────┴────────┐ │ │ VP I ───────────────┐ │ │ ┌────────┴────────┐ ↑│ │↓ │ │ NP VP └─────────────┐ │ │ │ │ ┌────────┴────────┐ │ │ └────────│────────┘ NP VP │← 1. PSI: Verb wird finit ↑ │ ← ┌────────┴────────┐ │ │← 2. V2: finites Verb 3. Vorfeld- │ AdvP V → │ │ an die 2. Stelle besetzung │ └────┘ │ │ ← │ └────────────────────────────────────────────────────┘
Das Stylesheet style.css enthält alle Formatierungen in Form von Formatvorlagen, die nötig sind, um eine linguistische Arbeit zu verfassen. Um also die folgenden Anweisungen anzuwenden, muß das file style.css im selben Verzeichnis wie das html-File gespeichert werden.
HTML-Dateien beginnen mit folgendem Header, um sich auf dieses Stylesheet zu beziehen (die wichtige Zeile ist hervorgehoben):
<!doctype html public "-//w3c//dtd html 4.1 final//en> <html> <head> <title>title</title> <meta http-equiv="content-type" content="text/html; charset=UTF-8> <link rel="stylesheet" href="style.css" type="text/css" title="style_no> </head> <body>
Wir finden hier im HEADER lediglich zwei wichtige Angaben: (a) es gibt ein Stylesheet namens style.css; (b) dieser Text ist in UTF-8 kodiert (ein übliches Modell von UNICODE). Ansonsten sind keine weiteren Angaben in der html-Datei, alle Formatieranweisungen finden sich nur im style.css-File. Wir haben daher eine Textdatei (*.html) mit unserem Text und nur sehr wenigen Tags, und eine weitere (nicht zu bearbeitende) Datei style.css, die die Formatierung besorgen wird.
Es wäre auch möglich, das Stylesheet in der HTML-Datei einzubinden (so wie eine DOC-Datei sowohl die Formatvorlagen wie auch den Text enthält) -- doch das hat den Nachteil, daß man wiederum jede Datei extra ändern müßte, wenn man die Formatierung ändern möchte; und es wäre unübersichtlich für den Autor oder die Autorin. Wenn es nur EINE style-Datei für alle HTML-Dateien gibt, kann man die Formatierung global ändern, indem man diese eine Datei verändert. Und die Texte bleiben übersichtlich.
Im Folgenden die Liste der nötigen Formatvorlagen (für eine PS-Arbeit, einen Artikel oder ein Buch), wie sie in style.css definiert sein müssen; ich mag kurze Namen, damit sie möglichst wenig Platz wegnehmen, nicht stören, schnell geschrieben werden können. Ich verwende daher einen three-letter-code für die Formatvorlagen; man braucht nur folgende:
| <p class=tt1> | Titel 1 für Titel | |
| <p class=tt2> | Titel 2 für Untertitel | |
| <p class=tt3> | Titel 3 für Autor/in | |
| <p class=tt4> | Titel 4 für Weiteres | |
| <h1> | Überschriften 1 für Überschriften | |
| <h2> | Überschriften 2 für Überschriften | |
| <h3> | Überschriften 3 für Überschriften | |
| <h4> | Überschriften 4 für Überschriften | |
| <h5> | Überschriften 5 für Überschriften | |
| <h6> | Überschriften 6 für Überschriften | |
| <p class=toc01> | table of contents Stil 1 | |
| <p class=toc02> | table of contents Stil 2 | |
| <p class=toc03> | table of contents Stil 3 | |
| <p class=toc04> | table of contents Stil 4 | |
| <p class=toc05> | table of contents Stil 5 | |
| <p class=toc06> | table of contents Stil 6 | |
| <p class=abs> | Abstract der Arbeit (falls notwendig für Publikationen); ist eigentlich identisch mit by1, evtl. unnötig. | |
| <p class=by1> | body text erster Absatz (nach Überschriften, Tabellen, Bildern) | |
| <p class=by0> | body text (normal, d.h., erste Zeile eingerückt) | |
| <p class=qu1> | für abgesetzte Zitate; 01 = normales Zitat, abgesetzt | |
| <p class=qu2> | für abgesetzte Zitate; 02 = kursiv (z.B. für eine Übersetzung) | |
| <p class=qu3> | für abgesetzte Zitate; 03 = normal, Folgeabsatz | |
| <p class=qu4> | für abgesetzte Zitate; 04 = Zitat in einem Zitat | |
| <p class=ex0> | Sprachbeispiel; ex0 = allgemein | |
| <p class=ex1> | Sprachbeispiel; ex1 = Sprachbeispiel | |
| <p class=ex2> | Sprachbeispiel; ex2 = Glossierung | |
| <p class=ex3> | Sprachbeispiel; ex3 = Übersetzung | |
| <p class=ex4> | Sprachbeispiel oder Diagramme; fester Zeichenabstand | |
| <p class=pc1> | Abbildungen: dieser Absatz enthält ein Bild | |
| <p class=pc2> | Abbildungen: dieser Absatz enthält die Bildunterschrift | |
| <p class=hlf> </p> | Dieses Format ('Halbzeile') in dieser Form macht einen kleinen Abstand zwischen Absätzen. Das empfiehlt sich vor Tabellen etc.; ein oder mehrere solcher Zeilen an verschiedenen Stellen kann man beim Layouten in einer Textverarbeitung benützen, um den Seitenumbruch für einen Ausdruck zu verändern. In html selbst weitgehend unnötig. | |
| <p class=bib> | Bibliographische Angaben sind 'hängend' formatiert. | |
| <p class=li1> | Listen 1 | |
| <p class=li2> | Listen 2, eingerückt | |
| <p class=li3> | Listen 3, eingerückt | |
| <p class=li4> | Listen 4, eingerückt | |
| <p class=int> | = int(ern) = unsichtbare Absätze, enthalten Informationen, die nicht angezeigt oder (im Moment) nicht gedruckt werden sollen. | |
| <p class=ftn> | footnotes – es gibt in HTML keine Fußnoten, der größte Nachteil für die hier vorgestellte Methode. Man muß sie selbst verwalten (sammeln). |
Mehr als das braucht man nicht ... Jeder Absatz im Text muß zu einer dieser Kategorien gehören. Kein Absatz sollte keiner Kategorie zugeordnet sein. Wenn man dies beherzigt, ist jeder Text immer genau so formatiert, wie das stylesheet vorschreibt.
Die hier folgende Beschreibung kann man übergehen: das File style. css enthält einfach nur die Formatierungen der Formatvorlagen, die man im html-File verwenden möchte.
Am Anfang ein paar grundlegende Feststellungen: a) Hintergrundfarbe, b) allgemeine Zeichengröße; falls man das ändern möchte, muß man nur den HTML-Farbcode hier ändern, oder die Angaben verändern; für Details bitte CSS TUTORIALS konsultieren:
/* basics */ body { background: #FFC } p { font-size: 12pt; text-align: justify; font-face: times } li { font-size: 12pt }
Für die Titelei gibt es der Einfachheit halber einfach vier verschieden große zentrierte Stile:
/* titles ---- neue bezeichnungen */ .tt1 { margin: 15pt 0pt 15pt 0pt; font-size: 36pt; font-weight: bold; text-align: center; color: darkblue } .tt2 { margin: 25pt 0pt 15pt 0pt; font-size: 30pt; font-weight: bold; text-align: center; color: darkblue } .tt3 { margin: 25pt 0pt 15pt 0pt; font-size: 26pt; font-weight: bold; text-align: center; color: darkblue } .tt4 { margin: 25pt 0pt 15pt 0pt; font-size: 20pt; font-weight: bold; text-align: center; color: darkblue }
Kapitel und Abschnitte werden folgendermaßen definiert:
/* headings */ h1 { margin: 25pt 0pt 15pt 0pt; font-size: 20pt; font-weight: bold; text-align: left; color: darkblue } h2 { margin: 25pt 0pt 15pt 0pt; font-size: 18pt; font-weight: bold; text-align: left; color: darkblue } h3 { margin: 25pt 0pt 15pt 0pt; font-size: 16pt; font-weight: bold; text-align: left; color: darkblue } h4 { margin: 25pt 0pt 15pt 0pt; font-size: 14pt; font-weight: bold; text-align: left; color: darkblue } h5 { margin: 25pt 0pt 15pt 0pt; font-size: 12pt; font-weight: bold; text-align: left; color: darkblue } h6 { margin: 25pt 0pt 15pt 0pt; font-size: 12pt; font-weight: normal; text-align: left; color: darkblue }
Für das Inhaltsverzeichnis benötigt man diese Vorlagen:
/* table of contents */ .toc01 { font-size: 10pt; font-weight: bold; text-align: left; margin: 0pt 0pt 0pt 0pt } .toc02 { font-size: 10pt; font-weight: normal; text-align: left; margin: 0pt 0pt 0pt 20pt } .toc03 { font-size: 10pt; font-weight: normal; text-align: left; margin: 0pt 0pt 0pt 40pt } .toc04 { font-size: 10pt; font-weight: normal; text-align: left; margin: 0pt 0pt 0pt 60pt }
Der Haupttext hat erste Absätze (nach Überschriften, Zitaten, Beispielen und Tabellen) = by1 sowie normale (eingerückte) Folgeabsätze = by0; dazu kommen noch ein Stil für bibliographische Angaben = bib, ein Stil für schmale Abstände = hlf (entspricht "\vspace{}"), und einen Stil für abstracts:
/* body text */ .by0 { margin: 0pt 0pt 0pt 0pt; text-indent: 20pt; font-size: 12pt } .by1 { margin: 10pt 0pt 0pt 0pt; text-indent: 0pt; font-size: 12pt } .bib { margin: 0pt 0pt 0pt 25pt; text-indent: -25pt; font-size: 12pt } .hlf { margin: 0pt 0pt 0pt 0pt; text-indent: 0pt; font-size: 6pt } .abs { margin: 0pt 0pt 0pt 0pt; text-indent: 0pt; font-size: 12pt; text-align: justify }
Zitate (und deren Übersetzung, etc.) -- man braucht bis zu vier verschiedene Stile, am besten aber nur den ersten:
/* quotations */ .qu1 { margin: 6pt 25pt 0pt 25pt; font-size: 12pt; font-style: normal; color: blue } .qu2 { margin: 0pt 25pt 0pt 25pt; font-size: 12pt; font-style: italic; color: blue } .qu3 { margin: 0pt 25pt 0pt 25pt; font-size: 12pt; font-style: normal; color: blue } .qu4 { margin: 0pt 25pt 0pt 50pt; font-size: 12pt; font-style: normal; color: blue }
Spezialformate, die man eigentlich nicht braucht: man beachte "int", der wird nicht angezeigt:
/* special */ .adr { font-size: 10pt; text-align: justify } .int { color: white; background: blue; font-weight: normal; display: none } .vrs { margin: 0pt 0pt 0pt 40pt; color: green }
Abbildungen stehen immer in einem Absatz "pc1", und die Bildunterschrift steht im Absatz "pc2":
/* pictures */ .pc1 { font-style: normal; text-align: center } .pc2 { font-style: italic; text-align: justify }
UNDSOWEITER. Das kann man im Originalstylesheet nachlesen, beliebig verändern oder erweitern. Man braucht Listen, etc.. Eine Frage sollte hier auftauchen: Warum sind hier nochmal selbstgestrickt Funktionen definiert, die es eigentlich in HTML gibt? ANTWORT: Wenn man HTML mit CSS nach MS-WORD oder LIBRE-OFFICE.WRITE importiert, werden alle stylesheet-Angaben übernommen. HTML-Funktionen, auch wenn in CSS definiert, werden allerdings als harte Formatierungen in der Formatvorlage STANDARD eingelesen. Das wäre ein Informationsverlust. So werden absolut alle Formatierungen als Formatvorlagen übernommen, ohne daß irgendein System "mitdenkt" (und Mist baut).
Sprechen wir lieber von dem für Linguisten spezifischen Problem: Sprachbeispiele (interlineare Glossierungen) müssen in Tabellen gelöst werden, die Stile hierzu: ex0 für allgemeine Beispiele; ex1 ist die Beispielsprache, ex2 die Glossierung, ex3 die Übersetzung; ex4 ist für Diagramme.
/* language samples */ .ex0 { margin: 0pt 0pt 0pt 0pt; font-size: 10pt; text-align: left; font-weight: normal; font-family: Arial Unicode MS; color: blue } .ex1 { margin: 0pt 0pt 0pt 0pt; font-size: 10pt; text-align: left; font-weight: bold; font-family: Arial Unicode MS; color: blue } .ex2 { margin: 0pt 0pt 0pt 0pt; font-size: 10pt; text-align: left; font-weight: normal; font-family: Arial Unicode MS; color: blue } .ex3 { margin: 0pt 0pt 0pt 0pt; font-size: 10pt; text-align: left; font-style: italic; color: blue } .ex4 { margin: 0pt 0pt 0pt 0pt; font-size: 10pt; text-align: left; font-weight: normal; font-family: Courier New; color: blue }
Das ergibt die folgenden Formatvorlagen in der HTML-Datei:
ex0 Überschrift bzw. allgemeine Angaben zum Sprachbeispiel
ex1 Sprachbeispiel
ex2 Glossierung
ex3 Übersetzung
ex4 Sprachbeispiel mit fixed-width font (für Diagramme)
Das sieht in einem Beispiel für eine Glossierung (in einer Tabelle) so aus:
| (01) | Chinese | ||
| 我 | 愛 | 你 | |
| wo3 | ai4 | ni3 | |
| ich | lieb- | du | |
| Du liebst mich. | |||
Diese Tabelle sieht in HTML so aus:
<!BGNTBL!><p class=hlf> </p><table><colgroup><col width=75></colgroup>
<tr class=ex0><td>(01) </td> <td colspan=3>Chinese</td></tr>
<tr class=ex1><td> </td> <td>我 </td> <td>愛 </td> <td>你 </td></tr>
<tr class=ex1><td> </td> <td>wo3</td> <td>ai4 </td> <td>ni3</td></tr>
<tr class=ex2><td> </td> <td>ich</td> <td>lieb-</td> <td>du </td></tr>
<tr class=ex3><td> </td> <td colspan=3>Du liebst mich. </td></tr>
<!ENDTBL!></table>
Man kann also jede Zeile (tr) mit einer 'class' definieren, oder in jeder Zelle (td) mit 'p class=ex0'; letzteres wäre besser, weil 'tr class=ex0' von der Textverarbeitung nicht als Formatvorlage eingelesen wird.
Beispiel für ein Diagramm:
XP ┌──────┴──────┐ spec X' specifier/modifier ┌──────┴──────┐ X compl complement ←──── ────→ m-command c-command (m = 'modifier', c = 'complement')
Der HTML-Code dafür:
<!BGNDIA!><p class=hlf> </p><pre><p class=ex4>
XP
┌──────┴──────┐
spec X' specifier/modifier
┌──────┴──────┐
X compl complement
←──── ────→
m-command c-command (m = 'modifier', c = 'complement')
<!ENDDIA!></p></pre>
Wie schon gesagt, html-Files, die diese Formatvorlagen verwenden, können problemlos in eine Textverarbeitung importiert und dort für den Druck vorbereitet werden. Die Formatvorlagen bleiben dabei erhalten und können folglich auch dort global verändert werden. Es ist daher völlig sicher und kompatibel, mit html zu schreiben.
Folgendes Sprachbeispiel ...
| (01) | Chinese | ||
| 我 | 愛 | 你 | |
| wo3 | ai4 | ni3 | |
| ich | lieb- | du | |
| Ich liebe dich. | |||
... sieht intern so aus:
<! ========== BGN LGSAMPLE ========== !> <p class=hlf> </p> <table> <colgroup> <col width=75> </colgroup> <tr class=ex1><td>(01)</td> <td colspan=3>Chinese </td></tr> <tr class=ex1><td> </td> <td>我 </td> <td>愛 </td> <td>你 </td></tr> <tr class=ex1><td> </td> <td>wo3</td> <td>ai4 </td> <td>ni3</td></tr> <tr class=ex2><td> </td> <td>ich</td> <td>lieb-</td> <td>du </td></tr> <tr class=ex3><td> </td> <td colspan=3>Ich liebe dich. </td></tr> </table> <! ========== END LGSAMPLE ========== !>
Das schaut vielleicht kompliziert aus, man kann sich aber so ein Muster vorbereiten oder automatisiert umformatieren und immer wieder verwenden. Es ergibt, wie gesagt, auch in jeder Textverarbeitung eine gute Tabelle.
Erklärung: Das hlf-Element macht einen kleinen Abstand zwischen Tabelle und Text; das Element mit "!" ist ein Kommentar; die erste Spalte mit der Numerierung ist IMMER auf 50 pixel gesetzt; dadurch haben alle Sprachbeispiele dieselbe Einrückung; die erste Zeile in ex01, die zweite in ex02, die dritte in ex03: ex03, die Übersetzung spannt sich über alle Spalten (colspan=4).
Vergleich: Auch in einem Textverarbeitungsprogramm muß man eine Tabelle basteln. Für TeX/LaTeX gibt es zwei Pakete, die so eine Funktionalität unterstützen (gb4e, covington), aber das ist nicht weniger komplex:
\begin{example} \gll {erste einheit} {zweites} {und noch was} \\ {glosse} {glosse} {glosse} \\ \glt übersetzung übersetzung übersetzung \\ \end{example}
Beides sind Lösungen mit Tabellendarstellung. Die Klammern in LATEX stellen sicher, daß die richtigen Elemente untereinander zu liegen kommen.
Man kann auch TEXT2TAGS verwenden, dann kann man sehr einfache Tabellen nur bei Bedarf umwandeln:
| Dies ist eine Tabelle, die in TEST2TAGS umgewandelt werden kann. |||| | Spalte 1 | Spalte 2 | Spalte 3 | Spalte 4 | | Spalte 1 | Spalte 2 | Spalte 3 | Spalte 4 | | Spalte 1 | Spalte 2 | Spalte 3 | Spalte 4 | | Dies ist eine Tabelle, die in TEXT2TAGS umgewandelt werden kann. ||||
Wenn man mit EMACS arbeitet, kann man den "orgtbl-mode" verwenden, um menschenlesbare Tabellen jederzeit in HTML, LATEX oder andere Formate umzuwandeln. Das schaut so aus:
<!-- #+ORGTBL: SEND lgsample orgtbl-to-html | La | cas-a | de | su | tí-a | está | cerca | del | centro | | DEF:F:SG | house-F | GEN | POSS:3SG:M | aunt-F | be:3S | near | GEN:DEF:M:SG | center | --> #BEGIN RECEIVE ORGTBL lgsample <table border="2" cellspacing="0" cellpadding="6" rules="groups" frame="hsides"> <caption></caption> <colgroup><col align="left" /><col align="left" /><col align="left" /><col align="left" /><col align="left" /><col align="left" /><col align="left" /><col align="left" /><col align="left" /> </colgroup> <tbody> <tr><td>La</td><td>cas-a</td><td>de</td><td>su</td><td>tí-a</td><td>está</td><td>cerca</td><td>del</td><td>centro</td></tr> <tr><td>DEF:F:SG</td><td>house-F</td><td>GEN</td><td>POSS:3SG:M</td><td>aunt-F</td><td>be:3S</td><td>near</td><td>GEN:DEF:M:SG</td><td>center</td></tr> </tbody> </table> #END RECEIVE ORGTBL lgsample
HTML ist also nicht schlimmer als alle anderen Möglichkeiten. Am einfachsten ist es, sich selbst solche Tabellen einmal zurechtzulegen und sie dann immer wieder zu verwenden. — Weitere Beispiele nur zum Spaß:
| (XXx) | Publius Ovidius Naso, Metamorphoses 1,5-9 (Schöpfung und Weltalter) | ||||||
| ANTE | MARE | ET | TERRAS | ET | QVOD | TEGIT | |
| before | sea | and | lands | and | what | covers | |
| Ehe das Meer und das Land war und alles bedeckend der Himmel, | |||||||
| OMNIA | CAELVM | VNVS | ERAT | TOTO | NATURAE | |
| all | heaven | one:NOM | was | all:ABL | nature:GEN | |
| hatte Natur nur das eine Gesicht im kreisenden Weltall, | ||||||
| VVLTVS | IN | ORBE | QVEM | DIXERE | CHAOS: | |
| face:NOM | in | world:ABL | which | having:said | chaos | |
| Chaos genannt: ein rohes, noch unverdautes Gemenge, | ||||||
| RVDIS | INDIGESTAQVE | MOLES | NEC | QVICQVAM | |
| rude | wild-SOC | bulk-PL:F | nothing | any | |
| nichts als kunstlose Last, zusammengestaucht und zugleich wild | |||||
| NISI | PONDVS | INERS | CONGESTAQVE | EODEM | ||
| if:not | weight | unskillful | heaped:up-SOC | same | ||
| in sich entzweit: die Samen nicht richtig verbundener Dinge. | ||||||
| NON | BENE | IVNCTARVM | DISCORDIA | SEMINA | ||
| not | good:ADV | connected-GEN:PL | Zwietracht | seeds-PL | ||
| in sich entzweit: die Samen nicht richtig verbundener | ||||||
| RERVM. | |
| thing-GEN:PL | |
| Dinge. |
| (XXx) | Chinese example | ||||||||
| 因为 | 易于 | 操作, | 所以 | 单次 | |||||
| yīnwèi | yìyú | cāozuò | suǒyǐ | dān cì | |||||
| because | apt | operate | and-so | single | |||||
| 撤销 | 非常 | 有效。 | ||
| chèxiāo | fēicháng | yǒuxiào | ||
| revoke | very-much | effective |
| This facility is very effective because it is so simple to operate. |
| (01b) | Tibetan example | |||||||||
| སྔོན་གྱི་ | དུས་སུ་ | གྲོང་གསེབ་ | ཅིག་གི་ | ནང་དུ་ | གླང་ཆེན་ | རཱ་མུ་ | ཟེར་བ་ | གཅིག་ | སྡོད་ཀྱི་ཡོད་ཅིང་། | |
| sngon gyi | dus su | grong gseb | cig gi | nang du | glang chen | rah mu | zer ba | gcig | sdod kyi yod cing/ | |
| early-GEN | time-ILL | village | INDEF-GEN | in-ILL | elephant | Ramu | so-called | one | stay-CONN-EX:CJ-GER | |
Once up on a time there lived in a village an elephant called Ramu. | ||||||||||
Baumdiagramme kann man mit <pre> am einfachsten darstellen (nicht schön, aber sehr einfach; für Publikationen nicht geeignet):
NP / \ / \ DET N'' der / \ / \ AP N' / \ / \ / \ / \ AdvP A N XP -------------- / \ rasche Verkauf / \ \ Adv / \ \ auffallend NP PP *PP* / \ / \ / \ / \ / \ / \ DET N'' P NP P NP des / \ durch / \ in | / \ / \ | AP N' DET N'' PN / \ einen / \ London / \ / \ N AP N' Gemäldes / \ / \ / \ / \ PP A N *PP* / \ ausgebil- Ex- / \ / \ deten per- / \ P NP ten P NP in / \ in | / \ | DET N'' PN dieser / \ London / \ AP N' / \ / \ N Hinsicht
Vergleich: Das LaTeX-Paket qtree macht das viel besser, aber andererseits ist die Kodierung mühselig. Textverarbeitung bietet solche Funktionalität nicht (damit ist gemeint, daß die eingebaute Graphikfunktion keine gute Idee ist, um so etwas zu machen; solche Graphiken machen das File ziemlich unbrauchbar und inkompatibel). Für eine Publikation müßte man natürlich eine andere Lösung finden (LaTeX verwenden? Graphiksoftware?). Für die rasche Anzeige ist diese Lösung ausreichend. Schöner und vielleicht ausreichend auch für Publikationen ist die Darstellung mit graphischen Elementen in HTML:
NP ┌──┴──┐ DET N'' ┌──┴──┐ AP N' ┌──┴──┐ N NP/PP/S
CP ┌────────┴────────┐ XP C' ┌────────┴────────┐ C IP ┌────────┴────────┐ NP I' ┌────────┴────────┐ VP I ┌────────┴────────┐ NP VP ┌────────┴────────┐ NP VP ┌────────┴────────┐ AdvP V
CP ┌──────┴──────┐ XP C' ┌──────┴──────┐ C IP───────────────────────┐ ┌──────┴──────┐ CP NP I' ┌──────┴──────┐ ┌──────┴──────┐ XP C' VP I ┌──────┴──────┐ ┌──────┴──────┐ C IP NP VP ┌──────┴──────┐ ┌──────┴──────┐ NP I' NP VP ┌──────┴──────┐ ┌──────┴──────┐ VP I AdvP V ┌──────┴──────┐ NP VP ┌──────┴──────┐ PP V
Der Kode dafür ist jedenfalls sehr einfach:
<!BGNDIA!> <p class=hlf> </p><pre><p class=ex4> CP ┌──────┴──────┐ XP C' ┌──────┴──────┐ C IP───────────────────────┐ ┌──────┴──────┐ CP NP I' ┌──────┴──────┐ ┌──────┴──────┐ XP C' VP I ┌──────┴──────┐ ┌──────┴──────┐ C IP NP VP ┌──────┴──────┐ ┌──────┴──────┐ NP I' NP VP ┌──────┴──────┐ ┌──────┴──────┐ VP I AdvP V ┌──────┴──────┐ NP VP ┌──────┴──────┐ PP V </p></pre> <! ENDDIA!>
Auch in der Textverarbeitung gibt es damit kein Problem; man verwendet in diesem Fall einen Font mit fixierter Zeichenbreite (fixed-width font), z.B. unter MS-WINDOWS "Courier".
CP ┌───────┴───────┐ DP C' ┌────┴──┐ ┌────┴──┐ D NP C IP Der ┌────┴───┐ lacht3 ┌──┴──┐ AP N' NP I' ┌──┴──┐ ┌──┴──┐ e1 ┌──┴───┐ AdvP A N CP VP I Käfer ┌─┴──┐ ┌─┴──┐ e2>e3 NP C' AdvP Vi der4 ┌─┴──┐ e2 C IP ┌─┴──┐ NP I' e4 ┌──┴───┐ VP I ┌──┴──┐ sieht5 DP V ┌──┴──┐ D NP den ┌──┴──┐ AP N' ┌──┴──┐ ┌─┴────┐ AdvP A N CP Hund ┌─┴──┐ NP C' der6 ┌─┴──┐ C IP ┌──┴──┐ NP I' e6 ┌──┴──┐ VP I ┌──┴──┐ ist7 AdvP V blau e7
Sonderzeichen sind inzwischen kein Problem – wenn man mozilla/firebird/etc. verwendet. Es steht der ganze Unicode-Bereich zur Verfügung, WENN man einen passenden Font installiert hat; hier die meisten wichtigen Zeichen:
— A: À Á Â Ã Ä Å Æ à á â ã ä å æ Ā ā Ă ă Ą ą Ǎ ǎ Ǻ ǻ Ǽ ǽ Ạ ạ Ả ả Ấ ấ Ầ ầ Ẩ ẩ Ẫ ẫ Ậ ậ Ắ ắ Ằ ằ Ẳ ẳ Ẵ ẵ Ặ ặ Ã Å Æ ã ä å æ Ā ā Ă ă Ą ą ǣ ɐ ǎ ɑ ɒ ʌ ə ɐ ɘ ɚ ɞ ʚ — B: ḅ Ḇ ḇ ɓ ʙ β — C: Ç ç Ć ć Ĉ ĉ Ċ ċ Č č Č č ɕ ç ʗ — D: Ď ď Đ đ Ð ð ₫ ɖ Ḍ ʣ dz ʤ ʥ ɗ ɵ — E: È É Ê Ë Ē ē Ĕ ĕ Ė ė Ę ę è é ê ë Ē ē Ĕ ĕ Ė ė Ę ę Ě ě Ẹ ẹ Ẻ ẻ Ẽ ẽ Ế ế Ề ề Ể ể Ễ ễ Ệ ệ ǝ ɘ ɛ ɜ ɝ ẽ ʚ Ẹ ẹ Ẽ ẽ ɚ Ɣ ---- aɛ̯ — F: ɸ ₣ ſ — G: Ĝ ĝ Ğ ğ Ġ ġ Ģ ģ ǧ Ǵ ɡ ɟ ɠ ɡ ɢ ɣ χ ʛ — H: Ĥ ĥ Ħ ħ ɥ ɦ ɧ Ḥ ḥ ẖ ɥ ʜ ʰ ʰ ʱ — I: Ì Í Î Ï ì í î ï Ĩ ĩ Ī ī Ĭ ĭ Į į İ ı IJ ij Ï ï Ĩ ĩ Ī ī Ĭ ĭ Į į ı ɨ ɩ ɪ ǐ Ỉ ỉ Ị ị — J: Ĵ ĵ Ǐ ʝ ʲ — K: Ķ ķ ĸ ḳ Ḵ ḵ ʞ — L: Ĺ ĺ Ļ ļ Ľ ľ Ŀ ŀ Ł ł Ł ɫ ɬ ɭ ɮ ʟ ʎ ˡ λ — M: Ṁ ṁ Ṃ ṃ ɱ — N: Ń ń Ņ ņ Ň ň ʼn Ŋ ŋ Ñ ñ Ṇ ṇ ɲ ɳ ɴ — O: Ò Ó Ô Õ Ö × Ø ò ó ô õ ö ø Ō ō Ŏ ŏ Ő ő œ ɶ Õ õ ø Ō ō Ŏ ŏ Ő ő ɔ ɶ ɷ ɤ ˠ Ơ ơ Ǒ ǒ Ǿ ǿ Ọ ọ Ỏ ỏ Ố ố Ồ ồ Ổ ổ Ỗ ỗ Ộ ộ Ớ ớ Ờ ờ Ở ở Ỡ ỡ Ợ ợ — P: ɸ — Q: ʠ — R: Ŕ ŕ Ŗ ŗ Ř ř Ŕ ŕ Ŗ ŗ Ř ř ɹ ɻ ɽ ɾ ʀ ʁ ɺ ɼ ɿ ʀ ʁ ʳ ʴ ʵ ʶ — S: š Š ß Ś ś Ŝ ŝ Ş ş Š š Ș ș ʂ Ṣ ṣ ∫ ʃ ʄ ʅ ʆ ß ˢ Ś Ŝ ś ŝ Ş ş — T: Þ Ţ ţ ț ʈ Ṭ ṭ Ṯ ṯ ʦ ʧ ʨ ʈ ʇ Þ þ Ţ ţ Ť ť Ŧ ŧ — U: Ù Ú Û Ü ù ú û ü Ǔ ǔ Ǖ ǖ Ǘ ǘ Ǚ ǚ Ǜ ǜ Ũ ũ Ū ū Ŭ ŭ ŭ Ů ů ǖ Ű ű Ų Ʊ ʉ ʊ ʌ ũ ʋ ɯ ɰ Ũ ũ Ū ū Ŭ ŭ Ů ů Ű ű Ų ų Ụ ụ Ủ ủ Ứ ứ Ừ ừ Ử ử Ữ ữ Ự ự — V: Ṿ ṿ — W: ʍ ʷ Ŵ ŵ Ẁ ẁ Ẃ ẃ Ẅ ẅ — X: ˣ χ — Y: Ý ý ÿ Ÿ Ý ý ÿ Ŷ ŷ Ÿ Ȳ ȳ ʎ ʏ ẙ ỹ ʸ Ŷ ŷ Ỳ ỳ Ỵ ỵ Ỷ ỷ Ỹ — Z: Ź ź Ż ż ž Ž Ź ź Ż ż Ž ž ʑ ʓ ʐ ʑ ʒ Ʒ Ƹ Ẓ ẓ Ẕ ẕ — ʔ: ʔ ʕ ʖ ʡ ʢ ˀ ˁ ˤ — CLICK: ʘ — APO: ʹ ʽ ʾ ʿ “x” ʻxʼ — DIA1: ˄ ˅ ˇ ˈ ˉ ˊ ˋ ˌ ˍ ˎ ˏ ː ˑ ˓ ˒ ˓ ˔ ˕ ˖ ˗ ˘ ˙ ˚ ˛ ˝ ˞ ̥=kugeldrunter — TONE: ˥ ˦ ˧ ˨ ˩ ˿ ̲ — ARROW: ← ↑ → ↓ ↔ ↕ ↖ ↗ ↘ ↙ ↜ ↝ ↮ ↯ ↰ ↱ ↲ ↳ ↴ ↵ ↶ ↷ ↺ ↻ ↼ ↽ ↾ ↿ ⇀ ⇁ ⇂ ⇃ ⇄ ⇅ ⇆ ⇇ ⇈ ⇉ ⇊ ⇋ ⇌ ⇍ ⇎ ⇏ ⇐ ⇑ ⇒ ⇓ ⇔ ⇕ ⇖ ⇗ ⇘ ⇙ ⇚ ⇛ ⇜ ⇝ ⇞ ⇟ ⇠ ⇡ ⇢ ⇣ ⇤ ⇥ ⇧ — SYMBOLS: ☠ ☏ ∞ ≠ ≈ ≤ ≥ ✓ ✕ ✔ ✉ ₤ ₧ ÷ ˚ ˙ ˘ ₪ ☺ ☻ ☼ ♀ ♂ ♪ ♫
Für die Eingabe von Spezialzeichen gibt es keine einfache Lösung. Es gibt Listen online für besondere Schriftzeichen. Man muß es sich halt einmal zurechtlegen, was man braucht. Ich empfehle für Windows-Users die Verwendung der kostenlosen Software babelpad, ein kleiner Texteditor, der die Eingabe aller Unicode-Zeichen sehr komfortabel gestaltet: man kann das Zeichen anklicken und automatisch auch den Code dadurch schreiben.
Vergleich: LATEX erfordert spezielle Pakete für phonetische Schrift und sonstige Schriften und ist abhängig davon, daß jemand einen Font und ein Paket für LATEX geschrieben hat. Für phonetische Schrift gibt es mehrere Pakete (z.B. tipa), diese sind aber rein LaTeX-bezogen, und es gibt wahrscheinlich keine Konvertierungssoftware, sodaß diese Lösung zunächst einmal inkompatibel ist. Für andere Schriften ist die Lage abhängig von der Existenz entsprechender Pakete.
Beispielsweise ist das Paket ctib für tibetisch sehr gut, es ist aber nicht standardmäßig installiert, und der Font ist vielleicht auch noch nicht sehr schön. In HTML ist jede Unicode-Schrift für Tibetisch zugänglich. In BABELPAD kann man Transliteration in tibetische Schrift (und andere) umwandeln – Problem gelöst.
In Textverarbeitung führt die Verwendung verschiedener Schriften immer weniger, aber immer noch im Prinzip zu viel Formatierarbeit. Abhilfe schafft unter MS-WINDOWS die Verwendung des unfreien Fonts Arial Unicode MS, der sehr umfangreich, aber typographisch nicht sehr schön ist. Für phonologische Transkriptionen empfehle ich LINUX LIBERTINE (für alle Betriebssysteme), alternativ gibt es den Font vom SIL. Für andere Schriften gibt es jeweils Lösungen.
Man kann die HTML-Datei mit dem Browser in eine PDF-Datei umwandeln (print to pdf). Mehr Kontrolle hat man allerdings, wenn man die HTML-Datei nach MS-WORD oder LIBREOFFICE.WRITE importiert, dort noch Seitenzahlen etc. hinzufügt, und diese Version druckt.
Wenn man in mehreren Stylesheets dieselben Styles festlegt, kann man dieselbe Datei so oder anders darstellen. Ich habe vier Stylesheets:
– style.css = normal für Bildschirm
– style_bu.css = besonders bunt, für Bildschirm
– style_pr.css = zum Ausdrucken; Monographie
– style_pr2.css = zum Ausdrucken, kleiner; Artikel